First of all, excuse my English, please, which in fact is not even my first foreign language.
I am honored to be here and to have been asked to open this conference.
The title of my own contribution is "The web: bottomless cornucopia & immense garbage dump",
and in fact, as we will see, the web is both:
a shallow cornucopia of emptiness and a deep mine of jewels, hidden underneath tons of commercial garbage.
This contradiction is only apparent: only slaves and patsy zombies are
bound to wade up to their neck in the commercial mud that infests the web. Once you learn how to search,
the "cosmic power" of a seeker will allow you to cut through the web and find all the fruits of the cornucopia.
Rhetorical grandstanding? You'll judge by yourself afterwards.
This will be a talk about contradictions. I will try to fulfill
the impossible task of pointing out some of these contradictions and -at the same time- show some effective web-searching techniques, that
will (should) allow anyone interested to take advantage from some of the very contradictions we will see.
The organizers of this event have chosen to give me two slots, therefore I will keep
this introduction on a more "general" tone, and follow tomorrow with a more "concrete" oriented workshop.
Hence those that
wont be too bored today may chose to participate tomorrow to my "FFF Wizardry: Finding forbidden fruits" workshop,
while those among you that will have had enough of this searching stuff will be able to
switch to other talks.
Having two opportunities to talk to you is also convenient because I intend to touch MANY different
search-related fileds, maybe too many.
Most talks in this kind of conferences are (correctly) incentrated on some specific aspects. This one will -instead- touch many different facets. I would like
to show you -today and tomorrow- a BROAD palette of searching techniques: many different ways to fetch your targets.
It will be up to you, later on your own, to decide which
ones you want to deepen and which ones may rest aside or be forgotten.
A caveat:
some of the things we will see together today and tomorrow
may prove useful to the "security" community, yet they could be misinterpreted as 'malicious', 'inconvenient' or even 'slightly illegal'
in some "copyright obsessed" countries.
I am not, strictly speaking,
a "security expert", rather a sort of 'insecurity' buff.
Please also note that I'm not always going to be politically correct, a severe handicap of mine. For instance
I understand "copyright" as just "the right to copy" as much as one fancies. I may be wrong, of course,
but that's how I understand it :-)
Yet
I'll disclaim it now (and only once): I am a seeker and I just
explain how to search the web. And the web is full of "copyrighted material"
and of many other weird things. So take note:
I do not condone, nor promote, patents' infringement (a diffuse practice
that some useless lobbysts dare to call
"piracy"). The web
is quite international, yet every country has
its own -different- petty provincial laws. So get acquinted with the laws used during each
historical contingence in each little "country" you happen to live in,
and do respect them, or else move elsewhere: the world is big.
If you do respect laws (and this is of course up to you), some of the
queries listed below should not be used in some countries. You have
been warned. Enough: people should *always* respect laws, even the most stupid ones, or they should try to
change those laws. Breaking laws "from below" may be fun, but is mostly rather silly: clever people (and
all sorts of expensive lawyers)
find loopholes
instead.
Also -as you can see- no powerpoint in my talks:
there's no need to turn everything into a sales pitch, and
with powerpoint even the few pre-chewed "ideas", hidden inside the bambinesque noise,
are simplified to the point that they become redundant and unclear.
We'll use good ole html instead.
If anyone misses powerpoint, he may be comforted knowing that he will at least be able to
follow this talk on his own screen.
Enough clich�s: I would like to examine, with you, some of the most
startling contradictions of the web. It isn't just a matter of curiosity:
such findings may give us some clues about future developments, and -as we will see- may even
help us to improve a little our searching skills: as you may know,
knowing WHERE TO FIND an answer is tantamount to knowing the answer itself. And today's Internet is a truly huge concoction:
everything that can be digitized is there, from music to images, from documents to books, from software to confidential memos.
The stake is very high:
if we learn to search effectively (and evaluate correctly our findings)
the entire human knowledge will become available, at our command and disposal, no matter where, or how,
somebody may have "hidden" our targets.
Most searching techniques are -a posteriori- very simple.
Build on your own on them and you wont need no-one
no-more to explain you anything: you'll always quickly fetch your own
signals among the heavy commercial noise that contaminates and infects the web.
To search and to fetch our targets we will use most of the time simple querystrings. Here an example, useful to fetch -of course for free-
a very good 'anti-streaming' application
(more on anti-streaming techniques
later and tomorrow):
Please note that there's no point in 'writing down' such a querystring:
try instead to understand the reasons behind the querystrings we will see together, don't
just count on them as they are:
the specific arrows we will launch today will not remain "sharp" for long.
Every-time I use
a querystring to make a point during a lecture, that same
querystring is often re-used many times over a very short time span,
thus 'affecting' the web with a sort of
schroedinger's
cat effect: once you open the box and show it, the querystring may be dead.
Like arrows, our new sharp querystrings -once used- slowly become blunt. Do not worry:
your skill and understanding
of the web will allow you to produce new, sharper ones: as many as you want.
Another interesting contradiction of a commercial infested web is that those very databases that have been
created in order to sell (or to hoard) files (huge repositories of music files, books, images, software, you name it)
lay open , or -ahem-
"next to open",
at our disposal, once we learn some basic searching skills.
I have found such default accounts with their default passwords in almost every database I have visited.
Most admins allow such accounts to exists, whereby seekers (in fact any attacker) can easily gain access.
Often these default accounts also have critical system privileges which should be of some interest for such a security
oriented audience. I am sure you are all aware of the
Borland Interbase's
"politically correct" exploit. Here for instance, another interesting list of oracle_default_passwords.
The web was made for SHARING, not for selling and not for hoarding, so -as we will see-
its very "building bricks" deny
to the commercial vultures the possibility of enslaving parts of it. This is but one of many www-contradictions.
But we do not have always to resort to 'tricks': the 'real' web of knowledge
is still alive and kicking, albeit unconfortably buried underneath the sterile sands of the commercial desert. This is
very important for seekers, it means that we have a
'double' edge: we can exploit more or less freely all commercial repositories and
we are able to quickly find the relevant scientific public ones.
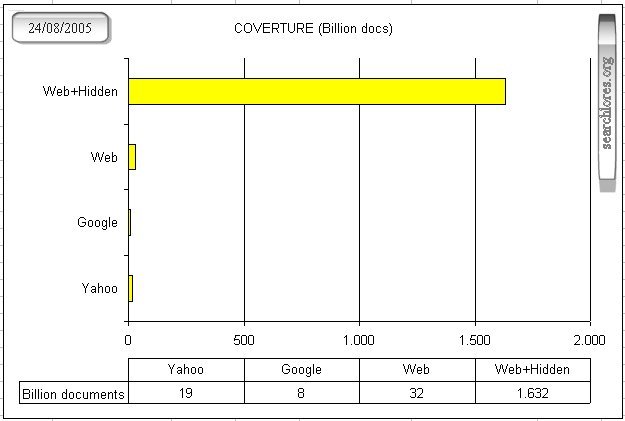
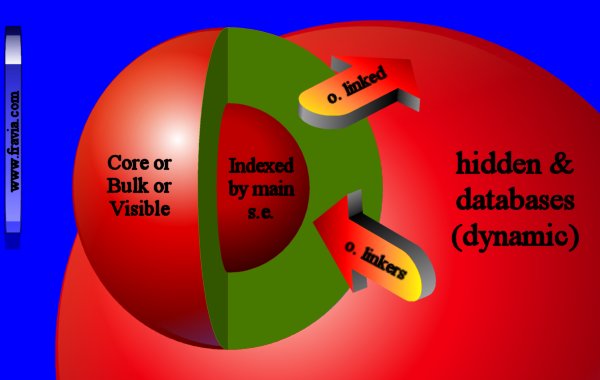
Nobody knows how big the web is. Estimates hover around 600 billion
documents. Note that there's an "invisible" (or "deep") "hidden databases"
web and a "visible" (or "surface") web.
The "hidden databases"
web is
made out of
dynamic, not persistent, pages.
The content of these searchable databases can only be found by a direct query.
Such pages often possess a unique URL address that allows them to be retrieved again later, yet
without a direct query, the database does not publish a specific page.
The "hidden databases" invisible/deep web is supposed to be (potentially) at least 500 TIMES bigger than the visible/surface web. This isn't too
far-fetched: just to
make an example, the Human Genome Project was adding in 2003 more than 7
terabytes (more than 7 times 10^12 bytes) of new data to its databases PER DAY!
Most researchers believe the visible "surface" bulk to be around 32 Billion (milliards) pages, only less than one half
of it covered by the main search engines. It is still growing, albeit at
a slower pace than some years ago.
"My index's bigger than yours, nah, nah, nah, nah"
Yahoo announced a month ago that it had indexed 19 Billion (milliards) documents.
Google now claims to index 11 Billion (milliards) pages (but the 'official' number is still 8,168,684,336 docs, so we'll stick to it), a few days after
Yahoo 'bigger index' claim, google doubled its number of indexed images,
(now -allegedly- 2,187,212,422).
We'll examine such Yahoo/Google indexes claims below, note however that all these data are next to irrelevant for seekers:
all the main search engines TOGETHER cover just LESS THAN ONE HALF (and probably less than a quarter) of the "visible" web, and only scattered
pages of the "hidden databases" (depending from link encountered on the static pages).
This limit is VERY IMPORTANT for searchers, combined with the fact that the main search engines do not overlap much (see below) it means
that you should use OTHER searching techniques instead of relying on the main search engines (or, even worse, on
google alone).
Search engines list only the first part of any BIG DOCUMENT:
the size varies.
Google had a famous limit of 101K, which was abolished last January, the new limit should be around 150K. These
limits are very annoying when dealing with large documents (or on-line books).
The DIAMETER of the web is supposed to be still around "19 clicks": two randomly chosen
documents on the web are on average 19 clicks away from each other.
This "shortest path" between two pages, measured using bots able
to track and count hyperlinks, was around 19 clicks at the beginning of the year 2000
and it should be around 23 clicks if we take account of the hidden databases. The diameter does
not increase proportionally with the growth of the Web. This is VERY IMPORTANT for searchers, it means
that any information is -and always will be- just a
few clicks away.
Outside linkers are fetched through klebing, stalking and social engineering
The hidden (and commercial) databases, the "deep/invisible" web, are accessed through
password breaking or guessing, social
engineering or, more simply, just seeking one of the many lists of
databases'
hardcoded passwords and default accounts passwords we have seen before (we may also delve, tomorrow, into some
common php scripts pestering php commercial vultures).
From most of the above, we can easily understand that getting rid of the "commercial noise" is not an option, when
searching effectively the web, it is a PRIORITY.
The web: a sticky quicksand Exploits & searching rules
get root with old stuff
CLEANING THE COMMERCIAL NOISE
Once upon a time, with most search engines, you could eliminate all those crap "*.com" sites adding the simple snippet -"*.com" in your querystrings.
Nowadays -for google- it does not work anymore: you have to use the ad hoc -site:com specifier.
I specified (now) because, yes, results amount diverge A LOT in different moments,
could depend from servers' overload or from the moon phase :-)
Some of you would probably think: great, then this is the way to go... just guess a correct queryterms sequence
and eliminate the ".com" sites, how simple and elegant...
Maybe when starting a broad 'el cheapo' search, but for a serious work
on ddos attacks you may find more relevant signal using specific SCHOLAR search engines (and limiting the query to the most
recent
months): ddos "june | july | august | september" +2005"
This is a MUCH more useful ddos query
However this is all simple googling: seeking, once more, is NOT (or only in part) made using the main search engines.
In order to understand searching strategies, a lore which you'll find relevant for your security hobbies and for your real life as well,
you have to grasp not only how the web looks like, but also how the web-tides move.
First of all the web is at the same time extremely static AND a quicksand, an oxymoron?
No, just another of the many contradictions we will see today.
See: Only less than one half of the pages available today will be available next year.
Hence, after
a year, about 50% of the content on the Web will be new. The Quicksand.
Yet, out of all pages that are still available after one
year (one half of the web), half of them (one quarter of the web), have not changed at all during the year. The static aspect
Those are the "STICKY" pages.
Henceforth the creation of new pages is a much
more significant source of change on the Web than the
changes in the existing pages. Coz relatively FEW pages are changed: Most Webpages are either taken off the web,
or replaced with new ones, or
added ex novo.
Given this low rate of web pages' "survival", historical
archiving, as performed by the Internet Archive, is of
critical importance for enabling long-term access to historical
Web content. In fact a significant fraction of pages accessible today
will be QUITE difficult to access next year.
But "difficult to access" means only that: difficult to access. In fact those pages will in the mean
time have been copied
in MANY private mirroring servers.
One of the basic laws of the web is that
EVERYTHING THAT HAS BEEN PUT ON THE WEB ONCE WILL LIVE ON COPYCATTED ELECTRONS FOREVER
How to find it, is another matter :-)
I am of course NOT giving
to the broad nasty public the real juicy messageboards (you may find them on your own if you learn how to search), yet,
for a start, apart well-known oldies like CERT, securityfocus
(bugtraq) and so on, you may want to have a look at
metasploit, Icat
and the awfully USA-oriented Common Vulnerabilities Exposures.
But I'm not an exploit expert, and I am sure that my friend Halvar Flake will have a lot to teach us about these matters
during this very conference :-)
Simple searching rules
Some simple rules when searching:
always use more than one search engine! "Google alone and you'll never be done!"
And yet there's a reason, after all, if I'm often (by all means just often) using google for my examples:
Indeed it is VERY EASY to understand that google's algos are better than Yahoo's or MSNsearch's ones.
Security experts could experimentally try the following search: making per host attack activity ranking
(adding making per to the host attack activity ranking query kills some noise)
Ok, let's have a look on
yahoo,
on google or on
msn and examine the relevance of the results
see?
Always use lowercase queries! "Lowercase just in case"
When in doubt, always use lowercase text, even for names. When you use lowercase, the search algos usually find both upper and lowercase results.
When you use upper case text, the search algos usually find only upper case results. This is NOT true for google (google assumes all search terms are
lowercase and ignores punctuation, hence whatever you input -unfortunately-
will be treated as lowercase), but it is still true for most correctly behaving search engines, so adhere to it.
e;g: When you search for clinton, you'll find clinton, Clinton, CLinton and CLINTON in your result pages.
However, when you search for Clinton, only pages containing Clinton will/should appear in the search results.
Go regional! "For Hindi stuff, nothing beats a Hindi
search engine:-)" (an
online english-Hindi dictionary may prove useful for non-Hindi savvy seekers)
For instance, for pirated software (and many other things) go chinese, and I do not mean only
Baidu and Netease/www.163.com -which have been censored.
A simple
"chinese google" will do: http://www.google.com/intl/zh-cn/, of course you will
also
need some useful translation tables (more on "languages searching" tomorrow):
Basically, you should move from general to particular and from particular to general all the time. From part to whole, from whole to part.
Remember that searching is a PROCESS, made out of different phases. You usually
begin with a broad query on some main search engines (more than one).
As you pick up information during your search, you will use it to modify or refine your query.
Once you have a nice palette of terms related to your target, you can begin to go inside the
web through regional searches, specialized searches,
irc searching, messageboards searching, target-relatedsearching
and so on...
You need to know something to find out something more.
And there is a huge difference between the "usual" searches and your own (few) "long term" searches.
These are the two/three "searching passions" that anyone has: those targets that
he most cherishes, for work or (better) for pleasure. While for the usual "everyday" searches it is true that if you do not
find what you are looking for in 15 minutes it probably
means that your search strategy is wrong, for any "long term search"
a week is not enough, a month is not enough,
a year is not enough. For my own searches I fear that my life wont be enough.
As said:
You need to know something to find out something more: this means that for those
targets you really cherish you will have to become an expert, both for searching and for evaluation purposes.
And -alas- the real world is not a frill/quick "for
dummies" abomination :-)
One of the most startling contradictions of today.
Given the current problems with holy crusades and mauros' bombings, and adding to this the
congenital urge of every "democracy"
to control his citiziens' fingers until the elbows ("people willing to trade their
freedom for security deserve neither and will lose both"), ISPs are now bound to keep track of ALL loggings and emails of
all their users, burning them on dvds and delivering them at once, for any whimsical reason, to the powers that be.
Even if you encrypt your communications with PGP (and very few people do it)
traffic analysis may still reveal what you're doing.
That's because the header of your encrypted packets discloses source, destination, size, timing, and so on.
Hence a typical ISP logs EVERYTHING and then some: which sites bozo has visited,
which pages he has seen, and which images, and how long, and when, and where...
Now
with a little grepping, a tag of traffic analysis and maybe also adding
his credit cards patterns, his airplane-trips & his supermarket fidelity card loggings (and whatnots)... op-la!
his complete web-life-personal-political and sanitary-psychological profile is ready and bullet-proof.
Is it?
Nope. In fact the other side of this very interesting contradiction
is "wardriving"
tor tunneling and pretty
good anonymity...
A relative guide to anonymity, by fravia+, Version September 2005
-----------------------------------------
RULES
buy laptop cash and elsewhere (not
with credit cards and not in areas where they know/remember you)
wardrive in another part of the town, not the one you live in
download only, if you upload, upload with care just upload anonymous things or
PGP encrypted stuff and use
tor tunneling
rotate your wifi card mac address at every access point: I use "Macmakeup"
use wardriving laptop ONLY FOR THAT, no personal data whatsoever on it
TECHNIQUES
Find speedy, beefy first wifi accesspoint with netstumbler: there are so many unprotected
at all that you don't even need to
bother firing a wep-packets-analyzer to crack their weak WEP-encryptions
connect, browse, download, all shields down, javascript, java, the whole bazaar: who cares?
ISP "A" will register everything "he" does.
work half an hour, download the helluja out of it, upload with care
walk/drive ten meters: change access point
ISP "B" will now register everything "another he" does.
work half an hour, download the helluja out of it, upload with care
walk/drive ten meters: change access point
...repeat at leisure...
(reformat hard disk -or, better, restore image- every week or so, just in case)
next day another part of the town, or another town :-)
and so on...
So it is incredibly easy to be 'somebody else' and then whomever wants to reconstruct your activities
will have to find (and path-reconstruct and join) quite a lot of different people loggings.
As I said in any big town you just need to move ten meters
to find another access point (a different person, a different ISP). I made myself a small experiment:
walking (15 minutes) from my home to my workplace I found -lo and behold-
136 different access points:
more than one half of them without WEP encryption at all (as if it would matter).
WEP encryption is a joke, and anyone using Kismet for GNU-Linux (source code here)
or Retina Wi-Fi scanner for Windoze can bypass it
pretty quickly. Traffic Injection, as my friend Cedric Blanchard pointed
out a couple of months ago in Montreal, has dramatically decreased WEP cracking achievement time. And of course any 'Security professional'
(and any 'Insecurity professional')
should in my opinion have a look at Biondi's Scapy.
But the real bigbrother/anonymiy contradiction is that there is not even the need to bypass weak WEP-encryptions:
you'll find a plethora of completely open
access points everywhere.
Provided you are a tag careful whit your personal data -especially when uploading- and provided
you remember that THERE ARE MANY OTHER IDENTIFIERS
in your box -and not only your wifi MAC_address- you may browse the web with some amount of relative anonymity.
Yep, what you saw was Belarc Advisor,
one of the many 'Audit/snooping' tools you may find useful to play with.
Many new search engines & everyone uses google "Google alone and your search is never done"
The main search engines DO NOT overlap a lot
We will go deeper into non-main search engines searching techniques tomorrow. In order to search effectively a seeker must
first of all master the main search engines. The most important ones are, at the moment,
google, msn and yahoo, but all the
s.e. listed in my Bk:flangeofmyth
are imho important (and I think we should at least add gigablast and exalead
to this not-exhaustive list.
But let's start with google, at a well deserved number one position. If you'r using google for web-searching purposes (not for
images or news finding), you may choose to use an IP-address instead of the http://www.google.com URL.
For instance
http://66.249.93.104/: one of the many real "googles" that
wont redirect you to your provincial crap, as it happens when you use
http://www.google.com URL.
The main reason google is more effective than most other search engines is its ability to correctly
nuke
all variations of a given URL that are dynamically generated from the same clown-server, a well-known SEOs spammer trick.
Search engine result quality is in fact FIRST a function of how the index is created.
Even so google's results are still HEAVILY SPAMMED, but the added bonus of such an approach, even
under heavy spam-flak, is a much more cleano results list than anybody else.
This said, search engine result quality is of course ALSO a function of how the algorithms weight the results. So after
eliminating dupes and fake URLs you still have to apply sound algos in order to fetch relevant results.
The main reason you should use more than one main search engine is that
search engines overlap FAR less than you would think. Recent studies (For instance Dogpile, April 2005)
point out that around 3/4 of the results of a given search are UNIQUE for each search engine.
So, please, do remember, every-time you pavlovianically use google to search, that
each main search engine�s results are largely unique: "Google alone and your search is never done".
Yahoo versus Google
"My index's bigger than yours, nah, nah, nah, nah"
I have prepared these data - that you wont find on the web elsewhere- for this Helsinki conference.
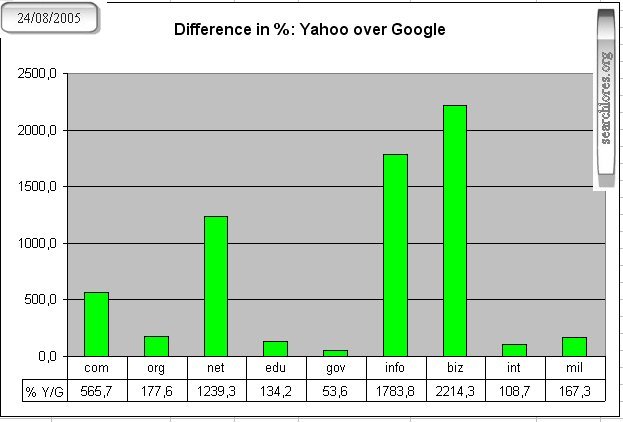
They demonstrate that -for the main search engines- index size is only loosely (and peraphs inversely :-)
related to the quality of results returned
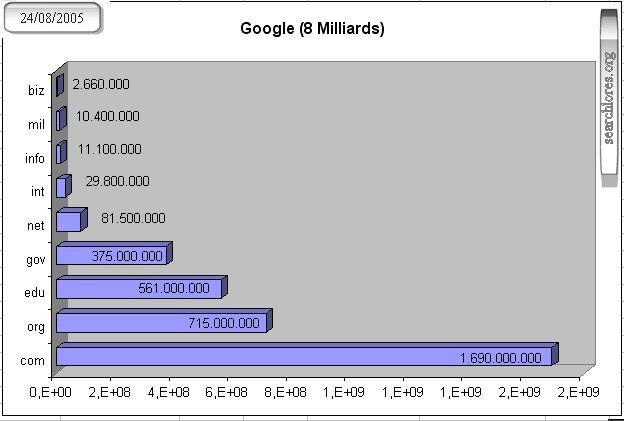
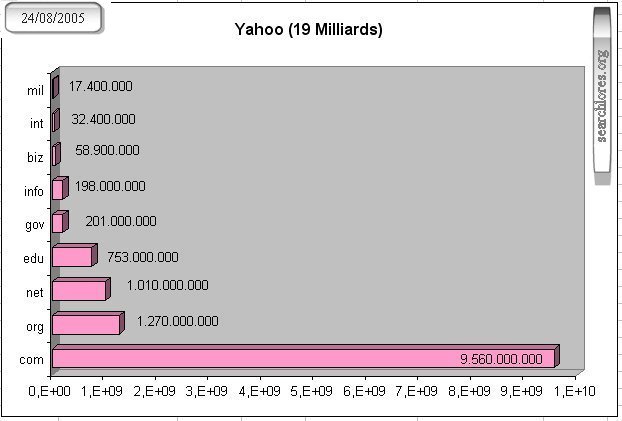
One month ago (August 2005) Yahoo announced suddenly to have indexed 19 Billion (milliards) documents. Clearly an attempt to dwarf Google's famous "8 Billion" (Milliards) sites.
Alas! No wonder that the results of (almost) any test search you may launch keep to be in Google's favor:
as the following data prove, the biggest increase in Yahoo's results seems to have been in "frills" domains.
For instance Yahoo now indexes 9.560.000.000
"com" domain documents, versus the 1.690.000.000
indexed by google. As you can see, the most striking differences, when regarding domains, are to be found
on crap & frill domains like "com", "info", "net" & "biz".
We can clearly see that the differences are less important for more content-rich domains like "edu", "org", "gov", "mil" and "int".
Here some graphs:
Note the sad preponderance of ".com" domains among those indexed:
Note the absolute preponderance of those very ".com" domains in Yahoo:
Would anyone in his right mind prefer a search engine that prefers "biz", "info", "net" and "com" domains?
Anyway, as you can see in the following graph, the COVERING of the web (especially taking account
of the hidden databases) is still rather meager BOTH for
Yahoo and Google:
Hence the importance of using OTHER METHODS to search the web, and not only the main search engines.
Here some hints (more about these techniques tomorrow):
1) go regional, then go regional again
2) go FTP
3) go IRC
4) go USENET/MESSAGEBARDS/BLOGS (yet remember that blogs are nothing more than messageboards where only the owner can start a thread,
this being the main reason -with few exceptions- of their quick obsolescence, short
duration and scant utility)
5) use homepages/rings/webarchives, cached repositories
6) use luring & social engineering
7) use stalking & trolling
BOOKS & Co (some weapons for seekers)
Gimme a rapid share, pleaz
We have already seen various querystrings: some "arrows" useful to find your targets.
To -quickly- fetch your targets, wading through the slimy commercial morasses of the web,
made specifically "ad captandum vulgus", and in order to "cut"
all the useless ballast you need a sword (and a shield).
The Sword
When you need to "cut" the Web your arrows, even the best ones, wont be enough:
you'll need first of all a sharp blade: a capable and quick browser.
That's the first and foremost
tool of a seeker. MSIE, Microsoft Internet explorer is a no-no-no, buggy, bloated and prone to all sort of nasty attacks. The
two current "philosophical schools" are either Firefox or Opera.
The Shield
Whichever browser you use, no sword will be enough without a SHIELD. And your shield,
and a mighty one for that, is proxomitron.
Proxomitron is a very powerful tool. Its power lies
in its ability to rewrite webpages on the fly, filter communications between
your computer and the web servers of the sites you visit, and to allow easy management of external proxy use.
Again: Proxomitron works by intercepting the HTML stream your
browser sees, and changes it on the fly. It runs as an "HTTP Proxy"
meaning it reads the HTML from the web and hands it off to your
browser. Since it lets you edit rules, if you
know HTML you will know what you're changing and may
create your own rules.
Here a
link to an old, but very good essay about proxomitron basic installation: anony_8.htm, and a link
to
another essay, Oncle Faf goes inside proxomitron about further fine-tuning.... Let's sum it up:
"Only morons 'just do it' without Proxomitron."
Now let's see some of Opera's advantages (the quick browser I
mostly use for a plethora of reasons)...
...
Among the many useful uses of proxomitron, its filters offer more speed to the seeker: as an example let's use proxomitron to nullify the
time waiting span imposed by rapidshare.
A Buffer Overflow Study - Attacks and Defenses (2002).pdf 470kbs
http://rapidshare.de/files/2305162/A_Buffer_Overflow_Study_-_Attacks_and_Defenses__2002_.pdf.html
Amazon Hacks - (O'reilly-August 2003).chm 2.83megs
http://rapidshare.de/files/1001242/O_Reilly_-_Amazon_Hacks__2003___TeaM_LiB___Share-Books.Net_.chm.html
Computer Vulnerability(March 9 2000).pdf 390kbs
http://rapidshare.de/files/2305190/Computer_Vulnerability_March_9_2000_.pdf.html
Crackproof Your Software(No Starch-2002).pdf 7.17megs
http://rapidshare.de/files/2305234/Crackproof_Your_Software_No_Starch-2002_.pdf.html
Credit Card Visa Hack(Cambridge Lab-2003).pdf 223kbs
http://rapidshare.de/files/2305239/Credit_Card_Visa_Hack_Cambridge_Lab-2003_.pdf.html
Google Hacking for Penetration Tester (Syngress-2005).pdf 13.7megs
http://rapidshare.de/files/2317399/Google_Hacking_for_Penetration_Tester__Syngress-2005_.pdf.html
Hack Attacks Revealed- A Complete Reference with Custom Security Hacking
Toolkit (Wiley-2001).pdf 8.25megs
http://rapidshare.de/files/2317485/Hack_Attacks_Revealed-_A_Complete_Reference
Hack IT Security Through Penetration Testing (Addison Wesley-2002).chm 4.96megs
http://rapidshare.de/files/2317600/Hack_IT__Security_Through_Penetration_Testing__Addison_Wesley-2002_.chm.html
Hack Proofing Your Identity in the Information Age (Syngress-2002).pdf 9.11megs
http://rapidshare.de/files/2317737/Hack_Proofing_Your_Identity_in_the_Information_Age__Syngress-2002_.pdf.html
Hack Proofing Your Network - Internet Tradecraft (Syngress-2000).pdf 2.94megs
http://rapidshare.de/files/2329542/Hack_Proofing_Your_Network_-_Internet_Tradecraft__Syngress-2000_.pdf.html
Hacker Disassembling Uncovered (A List- 2003).chm 4.72megs
http://rapidshare.de/files/2329577/Hacker_Disassembling_Uncovered__A_List-_2003_.chm.html
Hackers Beware (NewRiders -2002).pdf 4.62megs
http://rapidshare.de/files/2329607/Hackers_Beware__NewRiders_-2002_.pdf.html
Hackers Delight( Addison Wesley- 2003 ).chm 2.11megs
http://rapidshare.de/files/2329626/Hackers_Delight__Addison_Wesley-_2003__.chm.html
Hacker's Desk Reference.pdf 744kbs
http://rapidshare.de/files/2329629/Hacker_s_Desk_Reference.pdf.html
Hacking Exposed- Network Security Secrets and Solutions (MCGraw-Hill-2001).pdf 8.04megs
http://rapidshare.de/files/2369818/Hacking_Exposed-_Network_Security_Secrets_and_Solutions__MCGraw-Hill-2001_.pdf.html
Hacking Exposed- Web Applications (MCGraw-Hill-2002).pdf 7.76megs
http://rapidshare.de/files/2369872/Hacking_Exposed-_Web_Applications__MCGraw-Hill-2002_.pdf.html
Hacking Exposed- Windows 2003 Chapter 5.pdf 916kbs
http://rapidshare.de/files/2369895/Hacking_Exposed-_Windows_2003_Chapter_5.pdf.html
Hacking for Dummies (John Wiley-2004).pdf 9.50megs
http://rapidshare.de/files/2369943/Hacking_for_Dummies__John_Wiley-2004_.pdf.html
Hacking Guide v3.1[www.netz.ru].pdf 1.22megs
http://rapidshare.de/files/2382155/Hacking_Guide_v3.1_www.netz.ru_.pdf.html
Hacking-The Art of Exploitation(No Starch-2003).chm 1.43megs
http://rapidshare.de/files/411679/Hacking_-_The_Art_of_Exploitation.chm.html
How Thieves Targeted eBay Users but Got Stopped Instead(Interhack-June 2003).pdf 200kbs
http://rapidshare.de/files/2382182/How_Thieves_Targeted_eBay_Users_but_Got_Stopped_Instead_Interhack-June_2003_.pdf.html
Malware - Fighting Malicious Code (Prentice Hall-November 21 2003).chm 6.49megs
http://rapidshare.de/files/2382239/Malware_-_Fighting_Malicious_Code__Prentice_Hall-November_21_2003_.chm.html
Maximum Security, 3rd Edition(Sams-April 2001).chm 2.21megs
http://rapidshare.de/files/2382271/Maximum_Security__3rd_Edition_Sams-April_2001_.chm.html
Maximum Security_-A Hackers Guide to Protect Your Internet .chm 1.31megs
http://rapidshare.de/files/2382285/Maximum_Security_-A_Hackers_Guide_to__Protect_Your_Internet_.chm.html
Network Security Tools (OReilly- Apr 2005).chm 1.32megs
http://rapidshare.de/files/2382318/Network_Security_Tools__OReilly-_Apr_2005_.chm.html
PC Hacks(Oct 2004).chm 6.10megs
http://rapidshare.de/files/1437885/OReilly.PC.Hacks.Oct.2004.eBook-DDU.chm.html
PDF Hack(Aug 2004).chm 3.61megs
http://rapidshare.de/files/1693887/OReilly.PDF.Hacks.Aug.2004.eBook-DDU.chm.html
Practical Study Remote Access (Cisco-December 22, 2003).chm 2.50megs
http://rapidshare.de/files/2382422/Practical_Study_Remote_Access__Cisco-December_22__2003_.chm.html
Reversing Secrets of Reverse Engineering (Apr 2005).pdf 8.37megs
http://rapidshare.de/files/2369197/Wiley.Reversing.Secrets.of.Reverse.Engineering.Apr.2005.eBook-DDU.pdf.html
Secrets To Winning Cash Via Online Poker.pdf 233kbs
http://rapidshare.de/files/2394511/Secrets_To_Winning_Cash_Via_Online_Poker.pdf.html
Spidering Hacks(O'Reilly- October 2003).chm 1.38megs
http://rapidshare.de/files/1000252/OReilly.Spidering.Hacks.chm.html
Stealing the Network; How to Own the Box ( Syngress-2003).pdf 4.58megs
http://rapidshare.de/files/714044/Stealing_the_Network_How_to_Own_the_Box.pdf.html
The Art of Deception by Kevin Mitnick.pdf 5.19megs
http://rapidshare.de/files/2394816/The_Art_of_Deception_by_Kevin_Mitnick.pdf.html
The Art of Intrusion-The Real Stories Behind the Exploits of Hackers Intruders and Deceivers (Wiley- Feb 2005).pdf 3.06megs
http://rapidshare.de/files/985113/The_Art_of_Intrusion.pdf.html
The Complete History of Hacking.pdf 135kbs
http://rapidshare.de/files/2394847/The_Complete_History_of_Hacking.pdf.html
Tricks of the Internet Gurus (April 1999).pdf 5.66megs
http://rapidshare.de/files/2394924/Tricks_of_the_Internet_Gurus__April_1999_.pdf.html
Underground Hacking Madness & Obsession on the Electronic Frontier.pdf 1.47megs
http://rapidshare.de/files/2394936/Underground_Hacking_Madness___Obsession_on_the_Electronic_Frontier.pdf.html
Web Hacking- Attacks and Defence (Pearson Education-August 08, 2002).chm 6.32megs
http://rapidshare.de/files/2394976/Web_Hacking-_Attacks_and_Defence__Pearson_Education-August_08__2002_.chm.html
Windows Server Hack(O'Reilly - March 2004).chm 1.82megs
http://rapidshare.de/files/1693872/OReilly.Windows.Server.Hacks.eBook-DDU.chm.html
Windows XP Hacks (O'reilly- Auguest 2003).chm 5.18megs
http://rapidshare.de/files/1693126/O_Reilly_-_Windows_XP_Hacks.chm.html
Of course -la va sans dire- you should use such downloads only to quickly see if it is worth buying these books.
Alas! Rapidshare, while useful, has a silly commercial attitude with
an annoying "delaying" trick.
Let's have a look at it,
fetching a book, that could maybe prove of some interest for
some of the worthy colleagues that have gathered here today: http://rapidshare.de/files/1709371/Wiley.Reversing.Secrets.of.Reverse.Engineering.Apr.2005.eBook-DDU.zip.html here is an example of rapidshare 'delaying' javascript code, which runs on client side:
<script>var c = 58; fc(); function fc(){
if(c>0){document.getElementById("dl").innerHTML = "Download-Ticket reserved. Please wait " + c + ' seconds.
Avoid the need for download-tickets by using a PREMIUM-Account. Instant access!';
c = c - 5;setTimeout("fc()", 5000)} else {document.getElementById("dl").innerHTML = unescape('
%3C%68%32%3E%3C%66%6F%6E%74%20%63%6F%6C%6F%72%3D%22%23%43%43%30%30%30%30%22%3E%20%44%6F%77%6E%6C%6F%61%64%3A%3C%2F%66%6F%6E
%74%3E%20%3C%61%20%68%72%65%66%3D%22%68%74%74%70%3A%2F%2F%64%6C%31%2E%72%61%70%69%64%73%68%61%72%65%2E%64%65%2F%66%69%6C%65
%73%2F%31%34%33%38%37%35%39%2F%32%37%37%35%37%30%39%37%2F%4D%63%47%72%61%77%5F%48%69%6C%6C%5F%4F%72%61%63%6C%65%5F%41%70%70
%6C%69%63%61%74%69%6F%6E%5F%53%65%72%76%65%72%5F%31%30%67%5F%41%64%6D%69%6E%5F%48%61%6E%64%62%6F%6F%6B%2E%72%61%72%22%3E%4D
%63%47%72%61%77%5F%48%69%6C%6C%5F%4F%72%61%63%6C%65%5F%41%70%70%6C%69%63%61%74%69%6F%6E%5F%53%65%72%76%65%72%5F%31%30%67%5F
%41%64%6D%69%6E%5F%48%61%6E%64%62%6F%6F%6B%2E%72%61%72%3C%2F%61%3E%3C%2F%68%32%3E')
}}</script>
In this case you would just use following proxo filter (by Loki):
Name = "RapidShare"
Active = TRUE
URL = "*rapidshare.de*"
Limit = 256
Match = "(var count?)\1 = [#0:45]"
Replace = "\1 = 0"
The other limit of rapidshare, the 'just one download' limit (that I bet some of you have already
encountered in the past few minutes :-) can of
course also be circumvented, for instance using rotating anonymous proxies, a task made easy(*)
by our good ole PROXOMITRON.
Alternatively you can flush and request a new IP address:
Start --> run --> cmd.exe --> ipconfig /flushdns --> ipconfig /release --> ipconfig /renew --> exit
Erase your cookies and reconnect to rapidshare.
Note however that the rapidshare search above is JUST ONE EXAMPLE:
Rapidshare is one of many "upload repositories" where people can upload large files.
It allows unlimited downloads. There are many similar repositories: rapidshare.de/: 30 Mb max, forever but after 30 days unused the file is removed, daily download limit of 3,000 MB for hosted files YouSendIt: 1 Giga max, after 7 days or 25 downloads (whichever occurs first)
the file is automatically removed mytempdir: 25 Mb max, 14 days * 1200 free downloads, after that only from 23.00 to 7.00. Sendmefile: 30 Mb max, after 14 days the file is automatically removed Megaupload: 500 Mb max (!), forever but after 30 days unused the file is removed (like rapidshare) qfile.de: unfortunately boughtg by rapidshare and
closed a few days ago ultrashare.net/: 30 Mb max, forever but after 30 days unused the file is removed (like rapidshare) http://www.spread-it.com/: 500Mb - Forever or after 14 days if unused http://turboupload.com/: 70Mb - download delay in order to show pub http://www.4shared.com/: 100Mb - 10Mb per file Forever or after 30 days if unused
and so on..., there are also many "images repositories":
Morale of the whole story? Shap sword + Powerful shield (+ good arrows) = as many useful books (inter alia) as you wish.
Book searching: the "have string, will fetch" approach
"Over the last several months, publishers
have begun opposing the Google Print for Libraries program (http://print.google.com)
grumbling litigiously about copyright issues"
There's a whole section regarding books searching at searchlores,
and you can delve into it by yourself. Suffice to say that (almost) all books mankind has written
are already on the web somewhere,
and that while we are sitting here dozens of fully scanned libraries are going on line:
if you'r attentive enough,
and if your searching scripts are good, you can
even hear the clinking "thuds" of those huge databases going on line...
(anyway at the moment with books even banal arrows
will deliver whatever you want)
A small digression about scientific articles
"The contradictions of journal searching"
Now, let's imagine we need a given COMPLETE ARTICLE, not an abstract, a complete text, and we do not want to pay no clowns for that.
Let's imagine we want
something mathematic related, I haven chosen as examples ["polynomial"] and ["prime factorization"]
Most searchers would use the two most "common" search engines for MATHEMATIC-RELATED articles
of the visible web:
http://www.emis.de/ZMATH/, which you can use to start a search and
http://www.ams.org/mathscinet/search which you SHOULD NOT use, due to its commercial crappiness
Let's search for "polynomial"
Let's imagine we are interested in the
third result: "The minimum period of the Ehrhart quasi-polynomial of a rational polytope", alas! Now we would be
supposed "to pay" in order to consult/see/download it. But we'r seekers, right?
Let's use a part of the abstract in order to fetch our target in extenso: " called the Ehrhart quasi-polynomial of"...
see? Let's repeat this with any other article on this database...
So, we have seen how to bypass commercial yokes using the previously explained "long string searching" approach.
The funny thing is that the web is so deep that we do not need at all to go through such bazaars.
In fact the "open source" waves are already purifying the closed world of the scientific journals as well. Good riddance!
Let's search on The Front (arxiv.org), that
is slowly beating the euroamerican commercial bastards black and blue...
for instance: "prime factorization",
but, to keep our previous example, also: "The minimum period of the Ehrhart"... et voil�.
On one side the idiots that do not even let you search if yo do not pay up front (US-mathscinet) & the clowns that let you search, but then
want you to pay in order to fetch your results (EU-ZMATH)... even if we could still find as seekers our targets, it
is refreshing to know that there is, on the other side, coesisting on teh same web with the previous wankers, a complete search engine, with a
better more rapidly growing database and everything you need for free hic et nunc(the Front: "It freed anyone from the need to be in Princeton, Heidelberg or Paris in order to do frontier research").
So, once again, the web, our web is BOTH a bottomless cornucopia and an immense
commercial infested garbage damp, and -of course- you need to know how to search...
How deep is deep?
Examples of "web-multidepth"
"I've heard legends about information that's supposedly "not online", but have never managed to locate any myself.
I've concluded that this is merely a
rationalization for inadequate search skills. Poor searchers can't find some
piece of information and so they conclude it's 'not online"
The depth and quantity of information available on the web, once you peel off the stale and useless commercial crusts,
is truly staggering. Here
just some examples, that I could multiply "ad abundantiam", intended to give you "a taste" of the
deep depths and currents of the web of knowledge...
A database and a search engine for advertisements, completely free, you may enlarge (and copy)
any image, watch
any ad-spot.
Advertisements from Austria to Zimbabwe. Very useful for
for advertisement reversing.
Of course when you study advertisement debunking you should also take account of the EVOLUTION of advertisement, and here is
where sites like http://scriptorium.lib.duke.edu/adaccess/browse.html (1911-1956)
may come handy.
And what about a place like this? http://www.britishpathe.com/: "Welcome
to Version 3.2 of the world's first digital news archive.
You can preview items from the entire British "Pathe
Film Archive" which covers news, sport, social history and entertainment from 1896 to 1970"...3500 hours of movies!
and 12,000,000 (12 MILLIONS) still images for free!
Or what about a place like this?
Anno: Austrian newspapers on
line. 1807-1935: COMPLETE copies of many Austrian newspapers from Napoleon to Hitler...
for instance Innsbrucker Nachrichten,
1868, 5 Juni, page 1... you can easily imagine how anybody, say in Tanzania, armed with such a site, can prepare
university-level assignments
about European history of the late XIX century "ziemlich gr�h", if he so wishes.
And the other way round? If you'r -say- in Vienna and want access to -say- Tanzanian resources?
Well, no problem! UDSM virtual library (The University of Dar es Salaam Virtual Library),
for instance, and many other resources that you'll be able to find easily.
Remember -however- that on the web you always need to evaluate what you find!
CONCLUSIONS
Names and ethic
First of all I would like to draw your attention towards the paramount
importance of names on the web... and towards the importance of TEXT...
We have seen how easy it is to find books, music, images, software and documents on the web.
This is quite interesting, because it basically means that
the guardian of the light tower, the young kid in central africa and the yuppie in new york all have access to the
same resources: location is now irrelevant...
Yet remember that
there are not only files on the web, but also solutions... the airport noise example...
The ethical aspect of searching and the three laws...
An unjust society where first world and third world coexist in the same countries...
Developments
In the year 2000 the first flash memory cards had 256 Mb (10^6) chips. The most recent ones (NAND usb types memory)
have now reached,
just six years later, 16 Gigabytes (10^9) (and Samsung said that new flash cards
up to 32 Gigabytes are
expected already in 2006). The capacity has been doubled every year.
D'you remember the rice and the chessboard tale?
There are 64 squares on a chess board. If you double a chip of flash 64 times
you end up with more storagespace than there is in all of the universe :-)
Such a development means many things (inter alia that static is the way to go and that, hence,
harddisks and mobile storage devices � la DVDs are as dead as a Dodo)
it means -speaking storage- that with 16.000.000.000 bytes
you can have already now something like 16000/2 perfect mp3s
or 16*2 dvd hours of movies on a single flash memory, and this development
also means that you will have in 5 years time
as many terabytes as you like: the web in your pockets,
all the books of the world in your PDA. And what does it means for seekers?
It means that searching and evaluation techniques, both on the wide web and inside
your own repositories
will be more and more important.
Evaluation
Hence:
The paramount importance of evaluation...
Learning to discern CRAP and
learning to reverse advertisers' tricks
will be MORE and MORE important.
Your capacity of not being fooled, of understanding the rhetorical
tricks will be PARAMOUNT (even more than now... "scusate se � poco")
Your capacity to choose: in life and on the web.
The correct (useful, lasting) cloth or textile, the correct (tasty,
lasting) pear fruit, the correct (enlightening, lasting) book to
read,
the correct (involving, lasting) game to play. The common word for these physical things is probably that
LASTING adjective. And this will -I believe- be even more valid for
the web in your pocket in a few years, with all its terabytes of moving virtual quicksand.
So which conclusions?
STFW!
That's it.
Any questions?
----------------------------- FFF part ----------------------------
FFF part
----------------------------- FFF part ----------------------------
FFF: FINDING FORBIDDEN FRUIT linguistic sine qua non -1
This talk should help to "concretize" a little what we have seen together yesterday.
Let's begin with one of the "simple searching rules" we have seen yesterday
This can be fairly simple most of the time...
for instance a typical "science database" search could begin using ad hoc operators:
intitle:search intitle:science site:uk
Hence, going regional is simpler said than done if you do not know many languages.
So let's make it simpler done than said :-)
How to find useful searchstrings in (almost) any language by +fravia, Sommer 2005
(The following masks and appletts have been copyrighted by me under the GPL licence)
First of all let's find an interesting string in any of the following languages:
en, fr, de, it, nl, es, el, pt, sv, da, fi, cs, et, lv, lt, hu, mt, pl, sk, sl using the following search mask:
Yes, this is a mask used to retrieve EU-documents. You just input a (possibly long) searchstring in any of the EU 20
languages and then fetch quickly your results from ALL eu.int servers (or from google's cached copies if those servers
are too slow).
The EU has given public access to (almost) all its documents on line. This for searchers is of incredible importance: it opens the
path to BILLIONS of interrelated documents in 20 different european languages (and counting: ro and bg should be added soon) that
have been translated by HUMANS. So this is no machine translation, as you will see.
Note that the mask above doesn't simply add "site:eu.int" to your google searches, It also gives back
100 (instead of the default 10) results per
page and guarantees that no results regrouping algos will be applied. Another
filter imposes the UTF-8 charset (most accented
characters are thus allowed)
As you can see most results come from the europa server and from the server of the EP.
Let's click (it's just an example) onto P6_TA-PROV(2005)0102
and we will see the
snippet " to develop and strengthen the Agency's strategy for information and communication".
Now we could just change "en" in the URL of the previous document to "fi" and
obtain the same document in finn (o in any other
of the 20 languages), or we could use the following bookmarklet (devised by -ritz) that, being a bookmarklet, allows us to open a different document
starting from another document CLIENT-SIDE (btw, the deep security implications of this
kind of bookmarklets will, I hope,
be noticed by this audience :-)
Here
the
_FROM_ENGLISH bookmarklet. Bookmark the link and use it to obtain a bilingual display. Tested and working on Opera 8
And op-la! That's it.
Of course if the original documents (the ones you have searched for) are in a lanuage different from english, you'll have to use slightly
different bookmarklets:
the
_FROM_GERMAN bookmarklet,
_FROM_FRENCH bookmarklet,
_FROM_ITALIAN bookmarklet,
_FROM_SUOMI bookmarklet,
_FROM_SPANISH bookmarklet... and so on.
Uff... that's it. Now lets' use these tools to fetch juicy searchstrings... ...
LANGUAGES linguistic sine qua non -2
Languages knowledge is on the web of paramount importance.
Our
"english mothertongues" friends mostly underestimate this aspect. As we have seen, one of the
best ways to bypass the limitations of the main search engines is going local,
through multilinguism. As you can imagine, whole new
constellations of interesting targets can be accessed through -say- russian, chinese, arabic,
japanese and korean search engines.
I will make an example related to these latter.
A seeker should know that naver,
chol,
daum (powered by google),
empas (which automatically searches for images)
and ready (powered by wisenut)
are the main korean search engines.
There is of course also a
korean yahoo, a
korean msn, and a
korean google (this howeverer will give you the same results as
"any" google unless you specify in the URL &lr=lang_ko).
The interesting thing is that using
these very names you get a query that bypasses the SEOs' spam inside the results you would have
using a more obvious, but for this reason spammed, string: korean search engines
As an example of how powerful some on-line services can be
have for example a look at the following tool, something that you may use to understand a Japanese site:
RIKAI
An incredible jappo-english translator! http://www.rikai.com/perl/Home.pl Try it for instance onto http://www.shirofan.com/ See? It "massages" WWW pages and
places "popup translations" from the EDICT database behind the Japanese text!
for instance
http://www.rikai.com/perl/LangMediator.En.pl?mediate_uri=http%3A%2F%2Fwww.shirofan.com%2F
See?
You can use this tool to "guess" the meaning of many a japanese page or -and especially- japanese search engine options,
even if you do not know Japanese :-)
You can easily understand how, in this way, you can -with the proper tools- explore the wealth of results that the
japanese, chinese, korean... you name them... search engines may (and probably will) give you.
Whois reversing is important in general and can give you even cheap satisfactions in your
battles against spam because it usally allows some level of retaliation against email-spammers.
How?
Easy: check your email-spam, find the site they want you to visit through the spam (they wont put any valid email address
inside the spam, of course) and then slowbomb .... the responsibles.
As an example, the most recent spam nuked in my
dev/null folder, redirected readers to the clowns at
http://www.optinemailtoday.biz/.
If you check the site through whois http://www.whois.sc/optinemailtoday.biz
you'll find that this domain has just a PO box in Seattle, but also that their billing contact is
bsoloway@inorbit.com
A short search will dig out these documents and demonstrate that this is a well known spammer:
Robert Alan Soloway, operating in Seattle, Washington State, with his clown company "Network Internet Marketing",
1200 Western Ave, APT. 17-E, Seattle WA 98101, with the
work address nim@cyberservices.com... that you can
slowbomb
Slowbomb him to hell, and slowbomb inorbit.com's
email-addresses and kristin@hlglaw.com (an attorney that defended this spammer) as well for good measure :-)
3) Another google approach (by Mordred)
Here is a
way to gather relevant info about your target
"index+of/" "train.wav******" Useful to see date and size that follow your target name...
4) ElKilla bookmarklet (by ritz) try it right away (no more clicking, press DEL to delete and ESC to cancel)
Right click and, in opera, select "add link to bookmarks"
FFF: Fravia's copyrighted, trademarked and patented anti-EULA definitive solution
Is there a lawyer in the house?
Before beginning the next snippet, about streaming, we would like to
show how to operate in a totally legal (sortof) way.
iradio_setup.exe
(or maybe here: iradio_setup.exe
: iradio is a
internet radio grabber and ripper, a useful, but alas commercial, program that will allow anybody
to intercept and register on the fly any broadcasted mp3. It is therefore eo ipso a good anti-streaming tool.
Its protection routines are ludicrous, suffice to say that if you disassemble it
you'll find even the following inside its code:
"D:\Jobs\3alab\RadioGrab\src\protection\.\ASProtection\lc.h" Where we can see inter alia that the original name was probbably "RadioGrab".
but I wont go into its protection routines now, I just wish to demonstrate
"how to nuke a EULA", you know those END-USER-AGREEMENT-LICENSES that nobody reads when clicking
onto install files, even if -for all you know- they may impose you to sacrifice your first-born to their gods.
Apart prohibiting disassembly, a sin I cannot condone, IRADIO's
EULA carries the following surreal mumbo-jumbo:
All title and intellectual property
rights in and to the content that may be accessed
through use of this SOFTWARE PRODUCT remains the property of
the respective content owner and is protected by
applicable copyright or other intellectual property
laws and treaties. This EULA grants you no rights to
use such content.
Now, we cannot accept this, because, to be frank with you, the very reason we might want to
install this anti-streaming grabber on our laptop is to
grab music that may happen to be patented :-)
So we not only disagree, we STRONGLY disagree and do not accept this eula.
So let's fire our customizer,
and let's "strongly disagree" to this EULA before installing iradio...
From what you saw, follows my copyrighted, trademarked and patented anti-EULA definitive solution:
Either EULAs ARE legally binding, in which case this "EULA of ours" is
legally binding as well, or EULAs
ARE NOT legally binding, hence (as I always thought)
they are just pseudo-juristical high-sounding overbloated crap.
Quod erat demonstrandum: EULA owners -all over the world-
please choose, we'r happy either way :-)
FFF: The music contradiction
Rebuking streamers and censors (Small pirates and fat corporate scammers)
Since every music snippet you may even wish, from classic to jazz, is already on the web
(easy to find through simple search strings, for instance:
intitle:"index of/" "last modified" "mp3" lady madonna,
albeit this ease is INVERSELY PROPORTIONAL to the 'popularity' of your target)
noone having more cerebral matter than aubergines
is buying music anymore.
Sales are de facto broken (-33% in the last 4 years) and the big music monopoles are going berserk.
Streaming music (encrypted or through obfuscated formats) is one of the many confuse answers they
have devised.
Of course 'new' formats can be reersed and encrypted streams must be decrypted with a
key (hidden) on the consumer's computer, so these measures are ludicrous.
They may soon try to make it 'illegal' to record a stream through patents, but since
it was illegal in the first time to download pirated music, and noone cares, their chances
of success are nil. Just to make you an example, Baidu and Netease (http://www.163.com), two huge chinese search engines/portals,
have recently stopped, under american corporate pressure, their MP3 search functions.
Yet there are around 10.000 sites offering pirated music in China alone, and, knowing how to search, anyone can
bypass such chinese censorship as easy as when using google or the various other 'first wold' censored portals.
For instance using the -not yet censored- querystring
m4a "Server at" on Netease:
m4a "Server at"
or this slight variant of the now censored "index of" trick, at Baidu: mp3 "Port 80"
(for instance: mp3 "Port 80" eminem).
So we are now, first, examining how to find normal, "non streamed" music. Blogs, those almost
useless and mostly boring and (deservedly) short-lived messageboards where only the owner can start a thread, can be for once useful:
a completely new wave of music searching is due to the relatively recent
mp3 blogs phenomenon. this said its mostly a waste of time to visit blogs:
usually it is MUCH simpler to just fetch the music you
need from huge web repositories and easy to bypass commercial databases any time you fancy it.
More and more music snippets (and videos) are STREAMED on the web. While there are very simple ways to
defeat any streaming protections,
some good anti-streaming tools are a sine qua non on anyone's box.
In fact, due to the mp3 mass-histerya censorship, finding your music targets streamed on the web is �
nowadays even more easier than finding them inside some mp3 repositories.
Fittingly -I believe- for a security conference, I will show you today how to reverse two such tools: a general connections checker and
a streams downloader.
To individuate what exactly is going on during your seeking connections, without tedious studying of your ethereal or firewall
loggings,
you may choose to use a small traffic checker called ipticker:
a very useful tool, small, not intrusive, powerful.
Ipticker is useful in order to check connections and TCP/UDP data, hence
you can use it to check suspicious activities (for instance when visiting rogue web sites), and you can use it also to
quickly gather the real URL of all streamed files.
You can download here the old (and uncracked)
version 1.6. of ipticker.
They are at version 1.9
now, so I hope they'll be grateful for this kinda 'advertisement' of their (good) software and
pardon me the following look under the hood.
This older version of Ipticker was indeed *very badly* protected:
A quick grep for "U N R E G I S T E R E D V E R S I O N" will land us smack inside the following
useless "protection" routine (archaic, I know, but this is a talk for bourgeoises,
real crackers in the audience should please refrain from laughing). Only four instructions need a comment.
:4039BE E833DFFFFF call 4018F6 ; --> do incredibly complex calculations on the registration key
:4039C3 85C0 test eax, eax ; --> test result of incredibly complex calculations. Al=0?
:4039C5 7512 jne 4039D9 ; --> No: jne "good guy"
:4039C7 6824D34000 push 40D324 ; --> Yes: push "U N R E G I S T E R E D V E R S I O N" and flag "bad guy"
Should somebody want to be a "good guy" he may just
modify the ONE byte in red above,
turning that "jump if not equal" into
a "jump if equal" (74) instruction...
In order to "automate" the stream downloading itself, a
very useful program is STREAMDOWN, a streaming media download tool. It supports not
only HTTP and FTP download, but also most streaming media download protocols, such as RTSP,
MMS, MMSU, MMST. It also supports download resuming.
You can download Windows Media Streams (.ASF, .ASX, .WAX, .WMA, .WMV), Real Video/Audio Streams (.RM, .RAM, .SMIL) and/or .MP3
It is a useful program to counter
those clowns that happily stream music and films in order to avoid
people making copies of it (even legitimates copies for personal use),
but its registration routine is another classical example of a completely useless protection scheme, hence maybe of some
interest for this audience.
Here I present the older
version 3.3 of streamdown,
they are now at version 5.0, so I hope they'll be grateful
for this kinda 'advertisement'of their (good) software and
pardon me the following look under the hood.
A quick grep for "regcode" (or for "unregistered version") will land us smack inside this
"protection" snippet of the code (archaic stuff nowadays! Don't laugh please, software is still "protected" this way).
I have shortened the code for quicker comprehension:
:0040A5C4 68BE625000 push 005062BE <------ (Data Obj ->"RegCode")
... do stuff with & check length of previously entered strings "RegName and RegCode"...
:0040A5D5 E8A62E0200 call 0042D480 <------ StreamDown.NEW_00_KEYCHK_CSD: mov byte ptr [00507FB5], 01 if legit key
... test return from StreamDown.NEW_00_KEYCHK_CSD
:0040A5DE 0F84E2000000 je 0040A6C6 <------ towards exit with bad flag 00 if bad strings
... do irrelevant stuff...
:0040A601 FF5218 call [edx+18] <------ again: is it a legitimate code?
:0040A604 84C0 test al, al <------ test result of checking routine: this time equal (0) if legit
:0040A606 0F8587000000 jne 0040A693 <------ non equal? Horror: jump to bad guy and avoid registering
:0040A60C 66C745DC0800 mov [ebp-24], 0008 <------ registered legitimate paying user routine ----|
... do various good stuff for the legitimate registered user... |
:0040A627 BAC7625000 mov edx, 005062C7 <------ (Data Obj ->"Register to: ") |
... make clear he's registered and legit... |-- "good guy" routine
:0040A685 B001 mov al, 01 <------ good guy flag high on the pennon |
... prepare edx register ... |
:0040A691 EB3F jmp 0040A6D2 <------ avoid bad guy flagging & go to good exit -----|
:0040A693 66C745DC1400 mov [ebp-24], 0014 <------ (Jump from Address :0040A606): start code for the "bad guy"
:0040A699 BAD6625000 mov edx, 005062D6 <------ (Data Obj ->"Unregistered Version")
... do evil stuff, decrease counter and mark "bad guy" (or bad strings) with bad flag 00 ...
:0040A6D2 5B pop ebx <------ (Jump from Address :0040A691): prepare exit
... pop sequitur and exit
:0040A6D6 C3 ret
As anyone can see, a simple 0F8487000000 (je 0040A693) instead of that
0F8587000000 (jne 0040A693) will automagically transmute
bad guys into good guys (as unlock codes I used my nick and 12 random numbers as key,
if I am not mistaken). When will
software programmers learn some more useful protection approaches?
Cracking is anyway useless if you know how to search:
it wouldn't for instance be difficult to find a ready made crack for
this software (or for anything else). For instance:
Note that you may even use any ad hoc, non porn infested,
crack search engine.
But using ready made cracks is not elegant and hence "deprecated":
you should always crack your own software by yourself :-)
Now that you know a little more how to search, you would be well advised to apply some of the techniques
we have seen to find some thorough and up-to date info relaing to your security field: here an 'assignement' of
sorts:
WDASM's author, Peter Urbanik, Disappeared some years ago.
He is/was one of the greatest brains of our age. He devised Wdasm, a quick dissasmbler "cum" debugger, and he acted
alone, as a "one man band".
Hint: He's not a dentist :-)
So: Assignement:
Where is he now? What's he doing?
Find Peter Urbanik (apply your stalking, luring, combing, klebing and social engineering capacities :-)
----------------------------- material ----------------------------
material
----------------------------- material ----------------------------
Alternatively ,learn how to navigate through
[Google's cache] (without images if you want
some more relative anonymity, just add "&strip=1", this will give you the text version of google's cache)!
VERY useful: you find a lot of sites based on their own name, which is another possible way to get to your target...
In fact Netcraft is so useful that you may want to add a netcraft javascript ad hoc bookmarklet to your bookmarks :-)
"SLIDES"
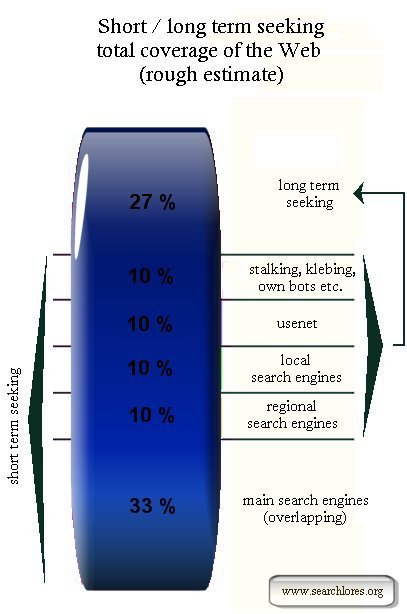
Structure of the web (the "classic" model)
Short and long term seeking
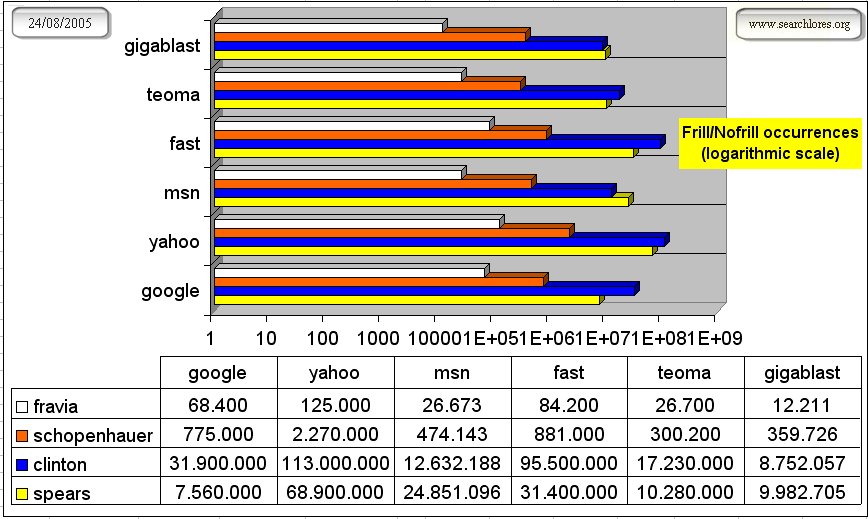
Frill oriented search engines: MSN=WORST, GOOGLE=BEST We have chosen as reference the following four terms: "spears" as "total crap frill" term, "clinton"
as "frilly news" term, "schopenhauer" as "content" term and myself as "weirdo/freak/marge" term.
Note how the WORST engine is MSN and the best is Google.
Comparing spears versus clinton (frill versus -frilly- news), Comparing spears versus schopenhauer (frill versus content) and
comparing spears versus fravia (frill versus freak).
Also notice how MSN is THE ONLY main search engine that has even more (as a matter of fact: twice) occurrences for "spears" than for "clinton".
NOTES
Note_1)
Well, actually not so easy if you do not know how to enable it:
open "proxy", rightclick on a proxy in the small window, choose advanced proxy setting,
choose "rotate proxy after every x connections", or "randomize rotations".
Note_2)
Another interesting bookmarklet for password breaking purposes is the "word frequency" bookmarklet word frequency
Note_3) Pestering php commercial vultures
In order to prepare your own "magic" tricks, and enter where you'r not supposed to (which is the "raison d'�tre" of the real seeker)
you'll have to know the most common scripts used on the web.
This is quite rewarding, but you'll have to "dirty your hands" with some commercial fetid scripts. Knowing their putrid php code can be *quite*
useful in order to reverse the helluja out of it when we encounter them in our wanderings.
Database scripts are -per definition- easy to retrieve,
here a small list
of the most easy to find on the web. They have been released long ago inside a package,
so I feel free to point to it,
since
anyone and his dog already fetched and used
them long ago :-)
Auto Gallery SQL,
AutoGallery Pro,
Autolinks Pro,
AutoRank Pro,
Calendar Now Pro,
ClickSee AdNow,
DeskPRO Enterprise,
Devil TGP,
DigiShop,
Done Right Bid Search Engine,
e-Classifieds,
ExplanationsSCripts.doc
faqmaster.zip
ImageFolio Commerce,
Magic News Plus,
Mojopersonals,
Nephp Publisher Enterprise,
NewsPHP,
Payment Gateway,
Photopost Php Pro,
PhotoPost,
PHP Live Helper,
PhpAuction PRO Plus,
phpListPro,
phpwebnews,
pMachine,
SmartSearch,
Stardevelop Livehelp,
SunShop,
webDate,
WebEdit Professional,
X-affiliate,
X-Cart.
Most of these scripts are in php, and really easy to reverse for penetration purposes.
Many more, different (and more clever)
ones,
are on the web alla round you. Go, fish, retrieve and multiply :-)
Note_4) Music streaming � la facile
The simpliest way is just to take a cable and to plug the output back to the input socket.
Take a look at the back of your PC. Hopefully you are seeing the socket holes of your soundcard. One of them is surely an output
( for your headphones ), one of them is input ( from a microphone? ). Most times they both
works with 3.5mm plugs. So if you have a cable with 3.5mm plugs in both sides
you can loop back the music ( or whatever output ) to the soundcard/PC.
However, this is not that simple:
you got to carefully mute any other sound output apart the WAVE out, then
in recording mute anything but the LINE IN.
then use a decent program like WAVELAB, and in wavelab set the rec level carefully to avoid noise or distortion.
the quality will be inferior compared to recording the digital stream since in any case
you record analog sound which was passed thru the AD/DA converter (which usually sucks unless you
own a very costly audio card).
however, in the majority of the cases all you need is just to open WAVELAB and just record the WAVE OUT mix :
you create a new track, press REC and select Wave Out as INPUT, you'll see the spectrogram moving etc, then when
finished cut the recording and save it as wav or mp3 et voila'.
doing this you just record the digital stream and NOT the analog i/o, so the only downturn
is that this stream is a frequency conversion but you'll hardly hear any difference from the original.